AI Ethics: Inverse Reinforcement Learning to the Rescue?
This post is Part 2 of a series of posts on AI ethics, beginning with my previous post on Asimov’s “Three Laws of Robotics” and culminating in a post describing a recent paper I wrote about interpretable apprenticeship learning.
In the previous post I argued that just programming moral and social norms into robots manually wouldn’t be sufficient for the task of AI ethics. Bots will also need the capacity to learn new moral and social norms, both through explicit moral instruction and through implicitly observing the behavior of others. This post is about inverse reinforcement learning (IRL), a machine learning technique that has been proposed as a way of accomplishing this. I’ll first explain what IRL is, why it has been proposed to solve the problem of learning moral norms from behavior, and some of its limitations. All this is leading towards Part 3 of this series, in which I’ll explain (and shamelessly plug) a paper of mine that was recently accepted at the Conference on Decision and Control.
What is inverse reinforcement learning (IRL)?
Reinforcement learning
My parents-in-law recently obtained an adorable golden retriever puppy named Ruby. Although very lovable, Ruby can also be quite naughty. She likes to bite just about everything, and she doesn’t always listen to instructions. For her to grow up to be a well-behaved dog (suitable for long off-leash walks in beautiful British Columbia), they will need to train her.
Training puppies is a long process. The trainer rewards the dog for performing desired behavior, and occasionally doles out punishments for disobedience. The rewards need to be consistent, and I’ve been told there’s an art to knowing exactly what aspects of the correct behavior to reward. Over time the good behaviors become habitual. Those of you who are parents can let me know if raising children is similar.
The beautiful thing about training animals is that given the time, resources, and skill of a good trainer, an animal can learn to perform all manner of complex behaviors for a reward (consider the stereotype of white-coated scientists watching rats run mazes for cheese). Perhaps inspired by this, some researchers decided that we could maybe train software programs to perform complex new tasks using the same techniques that we use for animals: reward and punishment.
We can think of animal behavior as trying to maximize the rewards they receive, in the long term. Now, animals (and people) are short-sighted, but still generally capable of stringing some actions together to obtain reward. (If a rat could only consider the next second’s reward, it would be unlikely to run the maze.) We can think of it as if the animals are trying to maximize the total sum of their rewards over time, but where future rewards are discounted (treated as less valuable than present rewards).
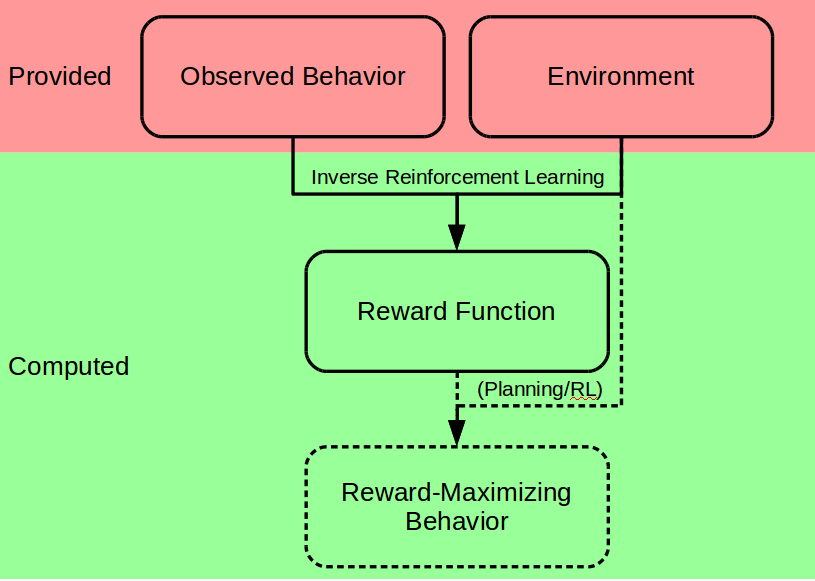
Reinforcement learning (RL) takes all these ideas, and turns them into a math problem that a software program can solve. To simplify things, we usually split time up into discrete chunks, called time steps. An agent (again, buzzword, referring to an AI program that can act) can perform one action per time step. Performing that action might change the state of the world (and how the state changes with each action might involve some randomness). The agent may also be given a reward or a punishment at each time step. Since we’re making this a math problem, the reward is just a number: a positive number to “reward” the agent, a negative number to “punish” it.
In RL environments, the reward received at a time step depends on the state at the last time step (call it $s$), the state at the current time step (call it $s’$), and the action that the agent just performed (call it $a$). The reward at each time step is specified using a reward function $R$ (which, given some $s,a,s’$, returns a single number $r = R(s,a,s’)$, the current reward). An RL agent wanders through its environment, performing action after action and receiving rewards and punishments according to the reward function. As it does this, it gradually learns to perform the right actions in the right states so as to maximize its long-term discounted reward.

Why “inverse”?
Reinforcement learning algorithms have been able to do some pretty impressive things lately, including beating the world champion at the game of Go and playing Atari games at near-human levels. They have even been considered for AI ethics, which isn’t surprising (after all, don’t we teach our children to do right by rewarding them for good and punishing them for evil?). Nevertheless, this approach suffers from some of the same “hardwiring” approaches discussed in my last post: the programmer has to specify the reward function, and that needs to include the right and wrong things to do in every possible situation, which is obviously not tractable. Additionally, (as with training dogs) there is something of an art to designing the reward function just right, so that the agent will do what you want while still being able to generalize.
One of the basic assumptions behind RL is that the reward function is specified by someone else, and then the agent does the behaving. What if the agent could instead watch someone else do the behaving, and try to come up with its reward function? Because this inverts the standard RL process (reward -> behavior vs behavior -> reward), it’s called inverse reinforcement learning (IRL). It’s also called apprenticeship learning, using the metaphor of the agent as an apprentice observing its master’s work. Because the reward function captures what the programmer really wants accomplished, being able to infer a reward function from behavior is like figuring out the goals of those whose behavior you are observing. Such an agent could watch good behavior, use this to deduce a reward function, and then use traditional RL to figure out how to maximize that reward function in the long term. This is considered better than mimicking the observed behavior directly, since (1) the agent might not see demonstrations of behavior in every possible situation, and (2) the agent might not actually be able to perform exactly the same actions as the demonstrator (e.g., if the demonstrator is a legged human and the agent a wheeled robot). Algorithms for IRL have been around since at least 2000.
How can IRL help with AI ethics?
By now, it should be obvious how IRL can help with AI ethics. Just think: we can teach agents to perform good behavior without having to spend a lot of time (a) writing down every little moral norm and social convention and (b) tuning and re-tuning a reward function! A robot can just watch people and other robots act in the real world, and then use IRL to figure out a reward function that explains why they might have done what they did. The more behavior the robot sees, the better its estimate of the reward function, and so the better it will behave.
This is why IRL has been touted as a key to AI ethics. The buzzword for this is “value alignment”: we can use IRL to teach robots to align their values with ours, so that what’s important to us will also be important to them. This approach has been advocated by (among others) Stuart Russell, the UC Berkeley professor who literally wrote the book on artificial intelligence.
What are the drawbacks of IRL?
Alas, IRL is not quite a silver bullet. Obviously IRL (or, for that matter, any approach seeking to learn from observed behavior) can’t be the only approach to learning moral norms, since people don’t always do what’s right (whereas we’d like robots to always do the right thing). I don’t even think IRL enthusiasts would encourage this, so that’s not the root of my concerns with IRL.
To me, there are three main problems with IRL: the temporal complexity of moral and social norms, and the context-dependence and interpretability of reward functions in general.
- Temporal complexity: For the sake of being able to do the math quickly, IRL (as well as traditional RL) make some assumptions about the reward function. Namely, they assume that the reward function is only based on the current state, the previous state, and the last action performed. In practice, some norms might be temporally complex. This means that the agent may need to know some information about its history (in addition to its state) in order to know what the right thing to do is. For example, whether you are obligated to pay your rent depends on whether you’ve already paid it this month. While the IRL enthusiast might respond that a robot could just augment its state to include the answer to the question “have I paid my rent this month?”, an agent learning from the behaviors of rent-payers couldn’t know a priori exactly how the state needed to be augmented. Playing it safe and making the state include all possible information about the agent’s history renders the problem completely intractable (that is, impossible to do in a reasonable amount of time). Thus, IRL cannot properly account for temporally complex norms.
- Context-dependence: Generally, RL researchers like to define the worlds in which their agents operate as narrowly as possible. The reason for this is obvious. Imagine that every time you decided what you wanted to eat for dinner, you had to think about the entire state of the universe. Clearly your choice of appetizer needn’t depend on the current state of affairs on Neptune; it also will probably be independent of favorite band of the Prime Minister of Sweden, and even of the current colour of your socks. It’s much easier to think of the agent as in different environments (or “domains”) depending on what sort of decisions it needs to make. The problem with IRL, then, is that the reward function is bound to the world in which the agent observes the behaviors. Think about it: $R(s,a,s’)$ depends on the what the states $s$ and $s’$ are, and the states will need to represent different sets of facts in different environments. It’s not clear how to translate such a reward function to an environment where states are completely different, even if the underlying moral principles are similar. IRL doesn’t do enough abstraction to be able to transfer its effects across domains.
- Interpretability: What IRL gives the agent is a reward function. This ultimately is just a relationship between some numbers and some other numbers (or between individual states and actions and a number, if you prefer). This means that if I am concerned about the behavior of an IRL-using robot and I want to see what it’s learned, I have to make sense of these numbers. Additionally, the more complex the agent’s representations of states and actions, the more hairy the reward function gets. Ideally, a robot learning moral norms would learn principles that a person could examine and easily evaluate for correctness: perhaps even principles that could be easily translated into human language!
These are a few of the hurdles that IRL must overcome in order to show itself a viable approach to moral learning. For a more thorough discussion of IRL and value alignment, see this paper written by my colleague Thomas Arnold, my advisor Matthias Scheutz, and myself. In the next part, I explain how my work starts to overcome these hurdles, creating interpretable apprenticeship learning by using temporal logic specifications.